
(Communicated by Xinmin Yang)
Abstract: The alternating direction method of multipliers (ADMM) has demonstrated its efficiency and well-understood convergence properties when applied to minimization problems where the objective function is the sum of two nonconvex separable functions and the constraint is linear. However, the requirement for global Lipschitz continuity of the gradient of differentiable functions, which is often impractical in nonconvex optimization problems, restricts its applicability across various domains. Recently, a novel Bregman ADMM has been introduced for two-block nonconvex optimization problems with linear constraints. This new Bregman ADMM not only removes the need for global Lipschitz continuity of the gradient, making it suitable for a broader range of practical problems, but also ensures that it can reduce to the classical ADMM in specific cases. Building on this Bregman ADMM, we address multi-block nonconvex separable optimization problems with linear constraints. We demonstrate that any cluster point of the iterative sequence generated by Bregman ADMM is a critical point, provided that the associated function satisfies the Kurdyka-Łojasiewicz inequality. Additionally, we present sufficient conditions to ensure both the convergence and convergence rate of the algorithm.
(Communicated by Xinmin Yang)
Abstract: Solving the distributional worst-case in the distributionally robust optimization problem equivalent to finding the projection onto the intersection of simplex and singly linear inequality constraint. This projection is a key component in the design of efficient first-order algorithms. This paper focuses on developing efficient algorithms for computing the projection onto the intersection of simplex and singly linear inequality constraint. Based on the Lagrangian duality theory, the studied projection can be obtained by solving a univariate nonsmooth equation. We employ an algorithm called LRSA, which leverages the Lagrangian duality approach and the secant method to compute this projection. In this algorithm, a modified secant method is specifically designed to solve the piecewise linear equation. Additionally, due to semismoothness the resulting equation, the semismooth Newton (SSN) method is a natural choice for solving it. Numerical experiments demonstrate that LRSA outperforms SSN algorithm and the state-of-the-art optimization solver called Gurobi. Moreover, we derive explicit formulas for the generalized HS-Jacobian of the projection, which are essential for designing second-order nonsmooth Newton algorithms.
(Communicated by Xinmin Yang)
Abstract: We investigate the following distributed convex optimization problem:
where $\tilde{s} \in {\mathbb{R}^n}$ is the global decision variable and the local objective function ${f_i}:{\mathbb{R}^n} \to \mathbb{R}$ belongs to agent $i$. All agents are nested in a strongly connected directed graph. The goal of $m$ agents is collaboratively to find the global minimizer of the problem (1) through local communication with their neighbors. Assuming that each agent $i$ has a local copy $s^i$ of the global decision variable $\tilde{s}$, the problem (1) can be equivalently written as:
${\min }\limits_{s \in {\mathbb{R}^{nm}}} f( s ) = \sum\limits_{i = 1}^m {{f_i}( {{s^i}} )}$ (2)
${\rm{s.t.}} \ {s^i} = {s^j}, \ \forall i,j = 1, \ldots ,m,$
where $s = {[ {(s^1)^{\mathsf{T}},(s^2)^{\mathsf{T}}, \ldots ,(s^m)^{\mathsf{T}}} ]^{\mathsf{T}}} \in {\mathbb{R}^{nm}}$. We propose a unified and accelerated version of distributed gradient methods to solve the problem (2).
Since the agents exchange the information over a directed graph, we consider the row-stochastic weight matrix $W = [ {{w_{ij}}} ] \in {\mathbb{R}^{m \times m}}$ associated the graph which satisfies the following conditions:
where $\mathcal{N}^i_{in}$ is the in-degree set of agent $i$. Define the matrix $L = [ l_{ij}] = I_m - W$ and the matrix $B = [ b_{jl}] \in {\mathbb{R}^{m\times m}}$ with $B1_m = b1_m$ for some $b \in \mathbb{R}$.
With the help of the row-stochastic weight matrix and the Nesterov's monentum acceleration technique, we propose a unified and accelerated version of distributed gradient methods (UADM). In our algorithm, each agent $i \in \mathcal{V}$ stores four variables $s_k^i \in {\mathbb{R}^n},x_k^i \in {\mathbb{R}^n},y_k^i \in {\mathbb{R}^m},u_k^i \in {\mathbb{R}^n}$. For $k \geq 0$ and all $i \in \mathcal{V}$, UADM is initialized with $x_0^i = s_0^i \in {\mathbb{R}^n},y_0^i = {e_i}\in {\mathbb{R}^m},u_0^i = 0_n$ and updates its variables as follows:
$x_{k + 1}^i = \sum\limits_{j = 1}^m {{w_{ij}}s_k^j} - {\alpha _i}\left( {\frac{{\nabla {f_i}( {s_k^i})}}{{{{[{y_k^i}]}_i}}} + u_k^i} \right)$ (3a)
$s_{k + 1}^i = x_{k + 1}^i + \beta_i ( {x_{k + 1}^i - x_k^I})$ (3b)
$y_{k + 1}^i = \sum\limits_{j = 1}^m {{w_{ij}}y_k^j}$ (3c)
$u_{k + 1}^i = u_k^i - \sum\limits_{j = 1}^m {{l_{ij}}} \left( { \frac{{\nabla {f_j}({s_k^j})}}{{{{[ {y_k^j} ]}_j}}} + u_k^j - \sum\limits_{l = 1}^m {{b_{jl}}s_k^l} }\right)$ (3d)
where $\alpha_i > 0$ is the local step-size, $ 0 \leq \beta_i< 1 $ is the local momentum coefficient.
When the parameters $\beta_i, b_{jl}$ in UADM take different values, UADM can include the accelerated method FROZEN as its special case and bring some new accelerated methods such as the accelerated versions of FROST and Li-Row. In contrast to the methods using the column-stochastic weight matrices, UADM based on the row-stochastic weight matrices does not require each agent to know its out-degree and is easier to implement in a distributed setting because each agent can assign appropriate weights to the received information from its in-neighbors.
If the step-sizes and the momentum coefficients satisfy some upper bounds, we prove that UADM has a linear convergence rate for smooth and strongly convex problems. The convergence result of UADM unifies the convergence results of distributed exact first-order algorithms, Li-Row, FROST and FROZEN.
Some numerical experiments on the distributed quadratic programming show that UADM significantly outperforms the nonaccelerated algorithm (Li-Row) as the condition number increases. Some numerical experiments on the distributed logistic regression problems demonstrate that our algorithm can achieve accelerated convergence in comparison with some existing distributed algorithms.
(Communicated by Xinmin Yang)
Abstract: This paper investigates an effective branch-and-bound algorithm for solving the generalized linear fractional multiplicative programming (GLFMP) problem. Initially, leveraging the structure of GLFMP, some variables are introduced to transform it into an equivalent problem. Subsequently, bidirectional linear relaxation is applied to the constraint functions of the equivalent problem, resulting in its linear relaxation problem, which is embedded into the branch-and-bound framework. Furthermore, incorporating tailored region reduction technique, we propose an output space branch-and-bound optimization algorithm. Additionally, the convergence and complexity of the algorithm are analyzed. Finally, the feasibility and effectiveness of the algorithm are validated using GLFMP instances ranging from specific to general cases.
This paper considers the following generalized linear fractional multiplicative programming problem:
GLFMP: $\begin{align*}\left\{\begin{aligned}&\min \;\; f(x)=\sum_{i=1}^p\gamma_i\,\prod_{j=1}^{N_i}(f_{ij}(x))^{\sigma_{ij}}\\&\mbox{s.t. } x\in X=\{x\in\mathbb{R}^n|Ax\leq b,x\geq 0\},\end{aligned}\right.\end{align*}$
where $f_{ij}(x)=\frac{n_{ij}^{\top}x+\alpha_{ij}}{d_{ij}^{\top}x+\beta_{ij}}$, $p$ and $N_{i}$ are natural numbers. $n_{ij}, d_{ij}\in \mathbb{R}^{n}$, $\alpha_{ij}, \beta_{ij}, \sigma_{ij}\in \mathbb{R}$, $A\in \mathbb{R}^{m\times n}$, $b\in \mathbb{R}^{m}$. $X$ is a non-empty, bounded and closed set. Assume that for any $x\in X$, $\min\{n_{ij}^{\top}x+\alpha_{ij}, d_{ij}^{\top}x+\beta_{ij}\}>0$ holds. Furthermore, when $\sigma_{ij}<0$, $\left(f_{ij}(x)\right)^{\sigma_{ij}}=\left(\frac{1}{f_{ij}(x)}\right)^{-\sigma_{ij}}$. Thus, for each $i\in I=\{1,...,p\}$, $j\in J_{i}=\{1,...,N_{i}\}$, assuming $\sigma_{ij}>0$ is not loss of generality. If ``min" in GLFMP is replaced by ``max", then
$\min_{x\in X}\sum_{i=1}^{p}\gamma_{i}\prod_{j=1}^{N_{i}}\left(f_{ij}(x)\right)^{\sigma_{ij}}=-\max_{x\in X}\sum_{i=1}^{p}(-\gamma_{i})\prod_{j=1}^{N_{I}} \left(f_{ij}(x)\right)^{\sigma_{ij}},$
which indicates that maximizing GLFMP can be transformed into the form of GLFMP.
An increasing number of scholars and experts are developing a keen interest in GLFMP and its various variants. One reason is that GLFMP and its variants have strong practical application capabilities in many areas. On the other hand, the complex structures of GLFMP and its variants result in them becoming non-convex problems, which often leads to them being NP-hard problems with multiple local optima instead of global solutions. This significantly hinders the search for a global optimum. Nevertheless, researchers have risen to the challenge and proposed numerous optimization algorithms.
The main purpose of this article is to design an output space branch-and-bound global optimization algorithm for the general form of GLFMP. In pursuit of this goal, we first introduce some variables and transform GLFMP through two resets to obtain its equivalent problem (EGLFMP). Subsequently, we approximate the constraints to obtain the linear relaxation problem of EGLFMP. Furthermore, in order to remove rectangular regions that do not contain the global optimal solution to a greater extent, region reduction technique is devised based on the structural characteristics of the equivalent problem and relaxation problem, aiming to expedite the convergence speed of the algorithm. Integrating the linear relaxation programming, region reduction technique, and branching strategy into the branch-and-bound framework yields an output space branch-and-bound algorithm distinct from existing algorithms. This algorithm can not only solve GLFMP, but also special variants of GLFMP mentioned earlier. Finally, we conduct a convergence analysis on the proposed algorithm and estimate the maximum number of iterations in the worst case. Numerous numerical experimental results are used to demonstrate the performance of the algorithm.
(Communicated by Xinmin Yang)
Abstract: In this paper, we concentrate on a broad class of large-scale nonconvex and nonsmooth optimization problems. We first propose a novel inertial stochastic Bregman proximal alternating linearized minimization algorithm (TiSBPALM), which employs variance-reduced stochastic gradient estimators. Subsequently, under the assumption that the objective function satisfies the Kurdyka-Łojasiewicz property and certain conditions on the parameters are imposed, we prove that the sequence generated by our algorithm converges to a critical point in expectation. Additionally, we provide the convergence rate for the iteration sequence. Finally, we conduct numerical experiments on sparse nonnegative matrix factorization and blind image-deblurring to verify the effectiveness of our proposed algorithms.
(Communicated by Xinwei Liu)
In this paper, we study the trust region subproblem with a linear cut over the complex domain ${\rm (TL)}$.
$\begin{eqnarray*}{\rm \left(TL\right)}~&\min_{w\in\Bbb C^n}&F(w)=\frac{1}{2}w^HAw+\mathcal{R}(b^Hw)\\~~~~~~~~~~~&{\rm s.t.}& w^Hw-1\leq 0,\\~~~~~~~~~~~&&\mathcal{R}(c^Hw)-d\leq 0,\end{eqnarray*}$
where $A\in\Bbb C^{n\times n}$ is an Hermitian matrix, whose eigenvalues are real numbers. We assume that $A\nsucceq 0$ and denote its eigenvalues by $\lambda_1\leq \lambda_2\leq...\leq\lambda_n$, where at least one of them is negative, i.e.,$\lambda_1<0$.
We also assume that the Slater condition holds, i.e., there exists $\hat{w}$ such that $\hat{w}^H\hat{w}<1,~\mathcal{R}(c^H\hat{w})<d$ holds.
We first reveal the hidden convexity property of {\rm (TL)} by proving that it is equivalent to a convex programming problem:
$\begin{eqnarray*}{\rm \left(C\right)}~&\min_{w\in\Bbb C^{n}}& P(w)=\frac{1}{2}w^H(A-\lambda_1I)w+\mathcal{R}(b^Hw)+\frac{1}{2}\lambda_1\\~~~~~~~~~~~&{\rm s.t.}& w^Hw-1\leq 0,\\~~~~~~~~~~~&&\mathcal{R}(c^Hw)-d\leq 0.\end{eqnarray*}$
As an approximation of ${\rm (C)}$, we turn to solve the following convex programming problem
which can be further equivalently reformulated as the problem ${\rm (AC^r)}$:
$\begin{eqnarray*}&{\rm \left(AC^r\right)}&\min_{z\in\Bbb R^{2n}} g(z):=\frac{1}{2}z^T(Q-\tilde{\lambda}_1I)z+q^Tz+\frac{1}{2}\tilde{\lambda}_1\\~~~~~~~~~~~&{\rm s.t.}& z\in S:=\left\{z^Tz-1\leq 0,~h^Tz-d\leq 0\right\}.\end{eqnarray*}$
Then we present a linear-time algorithm approximation scheme (in terms of the number of nonzero entries) for solving ${\rm (TL)}$ based on ${\rm (AC^r)}$. It mainly employs the eigenvalue approximation technique and Nesterov's accelerated gradient descent algorithm.
|
Algorithm 1 |
|
(a) Choose $\theta_0=\theta_{-1}\in(0,1]$, $z_0=z_{-1}\in S$. Let $k:=0$. |
|
(b) Let |
|
$y_k=z_k+\theta_k(\theta_{k-1}^{-1}-1)(z_k-z_{k-1})$ |
|
and $\nabla g_k=\nabla g(y_k)$. Update |
|
\begin{align*}z_{k+1}=\arg \min_{z\in S}~G(z)=z^T\nabla g_k+\rho\|z-y_k\|^2.\label{1}\tag{1}\end{align*} |
|
(c) Choose $\theta_{k+1}\in(0,1]$ satisfying |
|
$\frac{1-\theta_{k+1}}{\theta_{k+1}^2}\leq \frac{1}{\theta_k^2}.$ |
|
If the stopping criterion does not hold, update $k:=k+1$ and go to step (b). |
Then given the parameters $\epsilon>0$, $\delta>0$, with probability at least $1-\delta$ over the randomization of an approximate eigenvector oracle, we can find an $\epsilon$-approximation solution of ${\rm (TL)}$ in total time $O\left(\frac{N\sqrt{\|A\|}}{\sqrt{\epsilon}}\log\frac{n}{\delta}\right).$We show the efficiency of the algorithm by comparing it with CVX solver in the numerical experiment. We can also see from Figure 1 that for the same dimension, the required time increases linearly with density.
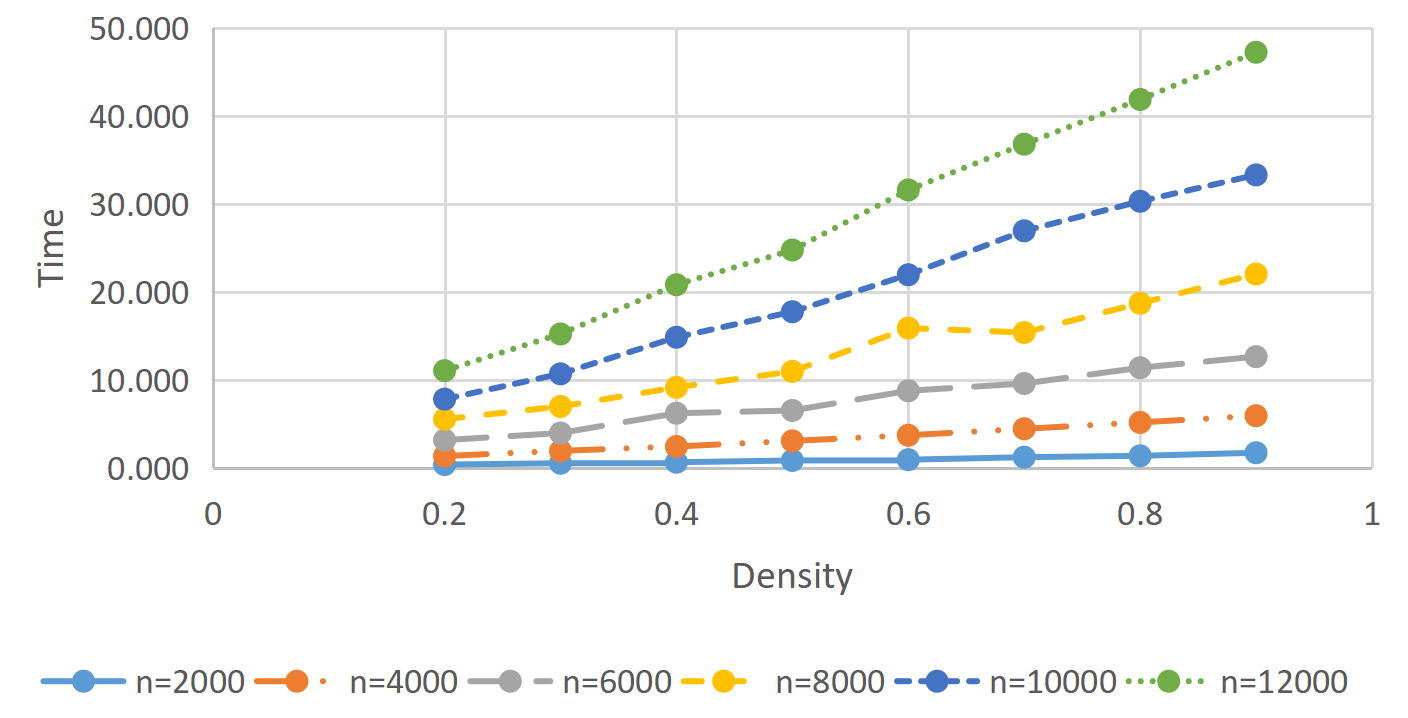
Figure 1: Computational time for different density with $\epsilon=10^{-6}$
Abstract:The Peaceman-Rachford splitting method (PRSM) can effectively solve two-block separable convex optimization problems with linear constraints. However, extending it directly to multi-block separable convex optimization problems lacks of convergence guarantees. To address this limitation, we introduce a generalized PRSM with an indefinite proximal term and a substitution step (GPRSM-S). The global convergence and the iteration complexity are analyzed by using variational inequality theory under mild assumptions. Finally, numerical experiments on the robust Principal Component Analysis (PCA) problem demonstrate that GPRSM-S has higher efficiency compared to previous approaches.
(Communicated by Xinmin Yang)
In this paper, we study a history-dependent quasi-variational hemivariational inequality as follows.
Problem 1. Find $u \in C(I;\Lambda)$ such that, for all $t \in I$, $u(t) \in K(u(t))$ and
$Au(t),v-u(t)\rangle + \varphi(Su(t),u(t),v)- \varphi(Su(t),u(t),u(t))$
Here $I=[0,+\infty)$ is an infinite time interval, $V$ and $X$ are reflexive Banach spaces, $Y$ is a normed space, $\Lambda$ is a nonempty subset of $V$, $C(I;\Lambda)$ stands for a set of all continuous functions defined on $I$ with values on $\Lambda$, $A: V \to V^*$ represents a nonlinear operator, $\gamma: V \to X$ is a linear continuous operator, $S: C(I;V) \to C(I;Y)$ is a history-dependent operator, $\varphi: Y \times V \times V \to \mathbb{R}$ is convex, lower semicontinuous with respect to its last argument, $j:X \times X \to \mathbb{R}$ is a locally Lipschitz functional with respect to its last argument, $j^\circ$ is the generalized directional derivative (in the sense of Clarke) of $j$, $K: \Lambda \to 2^\Lambda$ is a set-valued mapping and $f \in C(I;V^*)$ is given.
By applying a fixed point argument about history-dependent operators and the Gronwall inequality, we obtain a unique solvability result to the history-dependent quasi-variational hemivariational inequality in a space of continuous functions. In addition, when the data of the history-dependent quasi-variational hemivariational inequality are perturbed, sufficient conditions are given to guarantee that the solution sequence of the perturbed problem converges to the unique solution of the original problem.
(Communicated by Aifan Ling)
This paper introduces a new numerical method for solving nonlinear optimal control problems. In each iteration, the method linearizes the system and constraints based on the results from the previous iteration. Simultaneously, the objective function is approximated by its second-order Taylor expansion with respect to the control and state vectors, resulting in a linear-quadratic optimal control sub-problem. In solving the sub-problem, both the state and control vectors are approximated using Chebyshev series, where the coefficients of the Chebyshev polynomials are to be optimized. Furthermore, we approximate the known coefficient functions of the dynamic system and constraints using Chebyshev series. By the properties of Chebyshev polynomials, the sub-problem is finally transformed into a quadratic programming problem. We solve the dual problem of this optimization problem since it admits an exact solution. The effectiveness of the proposed method is demonstrated by examining three distinct types of optimal control problems. The numerical results conclusively illustrate that our approach outperforms the conventional iterative Chebyshev approximation method in terms of computation efficiency.

